GPU Programming With CUDA
by Wenwei Weng
Parallel computing using general purpose GPU is really taking off with advancement of technology from Nvidia, AMD, Intel. Especially Nvidia is dominating the field with variety of GPU offering and also software infrastructure CUDA (initially called as Compute Unified Device Architecture), which is a parallel computing platform and application programming interface (API) model. In this article, I share how GPU programming with CUDA looks like using UCS server with Nvidia GPU GRID K1

GPU Programming model
First introducing two terminologies:
- Host: The CPU (e.g. x86, ARM) and its memory (host memory)
- Device: The GPU (e.g. Nvidia GPU) and its memory (device memory).
There will be host code, which is executed in host CPU (e.g. x86); and there will be device code, which is loaded in host and push into GPU to run. The following diagram shows programming model and execution flow.
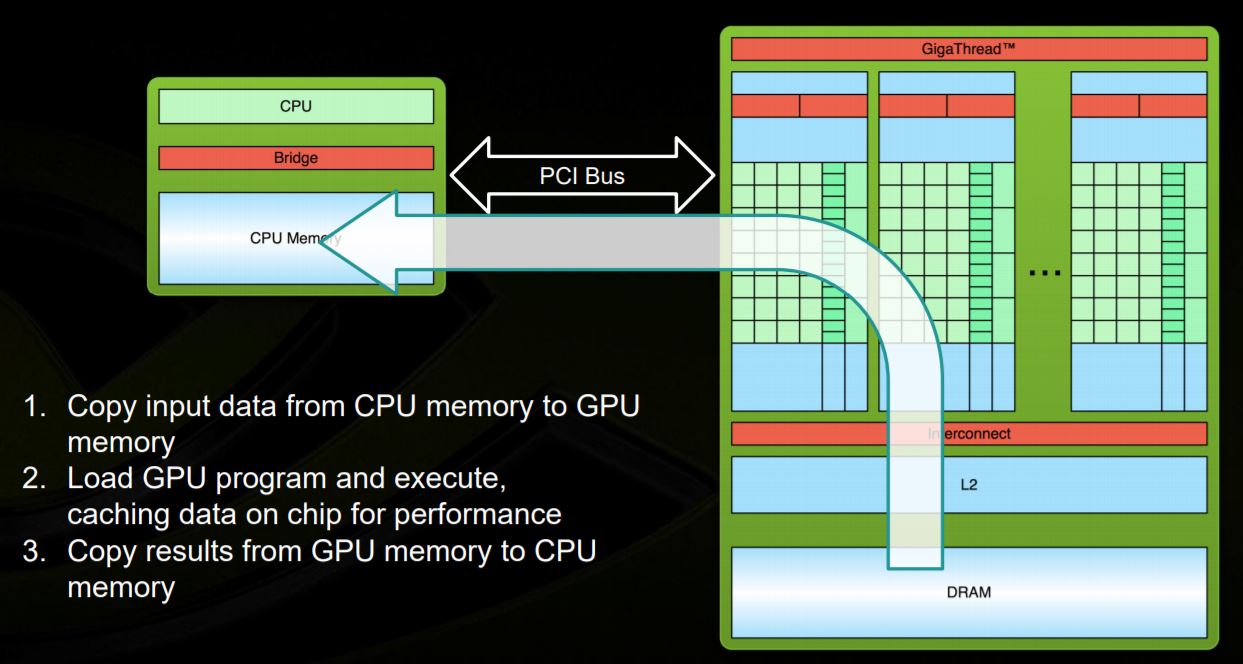
The basic hello world code is shown below:
cat hello.cu
__global__ void mykernel(void) {
}
int main(void) {
mykernel<<<1,1>>>();
printf("Hello World!\n");
return 0;
}The host code is same as usual, but the device code is marked with a new keyword “global”. host code invokes device code almost same as usual, except it adds «1,1» which means using one block and one thread, which isn’t interesting at all. Let’s trying something more interesting.
Running an example of vector additions using mutiple block and multiple threads
The main advantage of GPU computing is to have huge numbers of parallel executions. For that, CUDA introduces:
- Block: On the device, each block can execute in parallel, each block has index of “blockIdx.x”
- Thread: a block can be split into parallel threads, each thread has index of “threadIdx.x”
- Combining block with thread: the index is “threadIdx.x + blockIdx.x * blockDim.x”
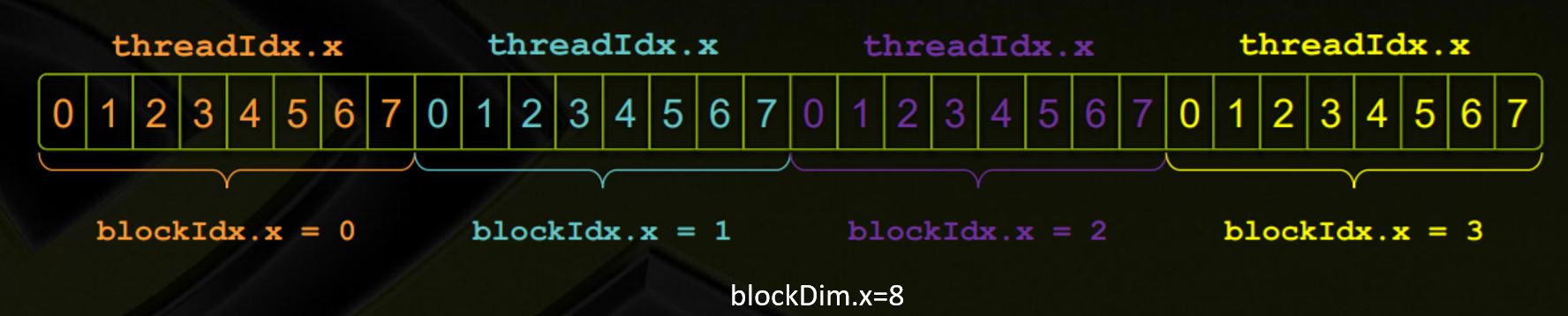
The below code creates two input arrays, which holds random integers, and the third array to hold result of addition, which is to be done by GPU.
First make sure we have Nvidia GPU GRID K1 and Nvidia compiler in place:
iot@iotg-ml-1:~/cuda-ex$ nvidia-smi
Fri Jun 2 06:41:22 2017
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 367.124 Driver Version: 367.124 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GRID K1 Off | 0000:85:00.0 Off | N/A |
| N/A 34C P0 13W / 31W | 0MiB / 4036MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 GRID K1 Off | 0000:86:00.0 Off | N/A |
| N/A 35C P0 13W / 31W | 0MiB / 4036MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 GRID K1 Off | 0000:87:00.0 Off | N/A |
| N/A 27C P0 13W / 31W | 0MiB / 4036MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 GRID K1 Off | 0000:88:00.0 Off | N/A |
| N/A 30C P0 12W / 31W | 0MiB / 4036MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
iot@iotg-ml-1:~/cuda-ex$
iot@iotg-ml-1:~/cuda-ex$ which nvcc
/usr/local/cuda/bin/nvcc
iot@iotg-ml-1:~/cuda-ex$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2016 NVIDIA Corporation
Built on Sun_Sep__4_22:14:01_CDT_2016
Cuda compilation tools, release 8.0, V8.0.44
iot@iotg-ml-1:~/cuda-ex$ Now let’s try following example:
iot@iotg-ml-1:~/cuda-ex$ cat gpu-add-vector.cu
#include <stdio.h>
#define N (2048*2048)
#define THREADS_PER_BLOCK 512
__global__ void add(int *a, int *b, int *c, int n) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
if (index < n)
c[index] = a[index] + b[index];
}
int main(void) {
int *a, *b, *c; // host copies of a, b, c
int *d_a, *d_b, *d_c; // device copies of a, b, c
int size = N * sizeof(int);
int i;
// Alloc space for device copies of a, b, c
cudaMalloc((void **)&d_a, size);
cudaMalloc((void **)&d_b, size);
cudaMalloc((void **)&d_c, size);
// Alloc space for host copies of a, b, c and setup input values
a = (int *)malloc(size); for (i = 0; i < N; i++) a[i] = rand()/10;
b = (int *)malloc(size); for (i = 0; i < N; i++) b[i] = rand()/10;
c = (int *)malloc(size);
// Copy inputs to device
cudaMemcpy(d_a, a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, size, cudaMemcpyHostToDevice);
// Launch add() kernel on GPU
add<<<N/THREADS_PER_BLOCK,THREADS_PER_BLOCK>>>(d_a, d_b, d_c, N);
// Copy result back to host
cudaMemcpy(c, d_c, size, cudaMemcpyDeviceToHost);
// Verify the result
printf("\n Verifying the result:");
for (i = 0; i < N; i++) {
if ((a[i] + b[i]) != c[i]) {
printf("Failed at %d: a=%d, b=%d, c=%d \n", i, a[i], b[i], c[i]);
break;
}
}
if (i == N) printf("PASSED!\n\n");
// Cleanup
free(a); free(b); free(c);
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
return (0);
}
iot@iotg-ml-1:~/cuda-ex$ nvcc gpu-add-vector.cu -o gpu-add-vector
nvcc warning : The 'compute_20', 'sm_20', and 'sm_21' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
iot@iotg-ml-1:~/cuda-ex$ ./gpu-add-vector
Verifying the result:PASSED!
iot@iotg-ml-1:~/cuda-ex$ Reference:
- https://www.nvidia.com/docs/IO/116711/sc11-cuda-c-basics.pdf
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
Subscribe via RSS