Explore GIT Internals
by Wenwei Weng
GIT is becoming widely used as SCM tool. I have been always interested in SCM tools which make me feel good if I know exactly where is my code and in case if I need made some change or track when/how the change is introduced. To get know better, I explored the internals of GIT, which is actaully very interesting.

GIT is actaully a content tracking tool. It is amazing it is used as version control tool. The following diagram shows the internal GIT structure:
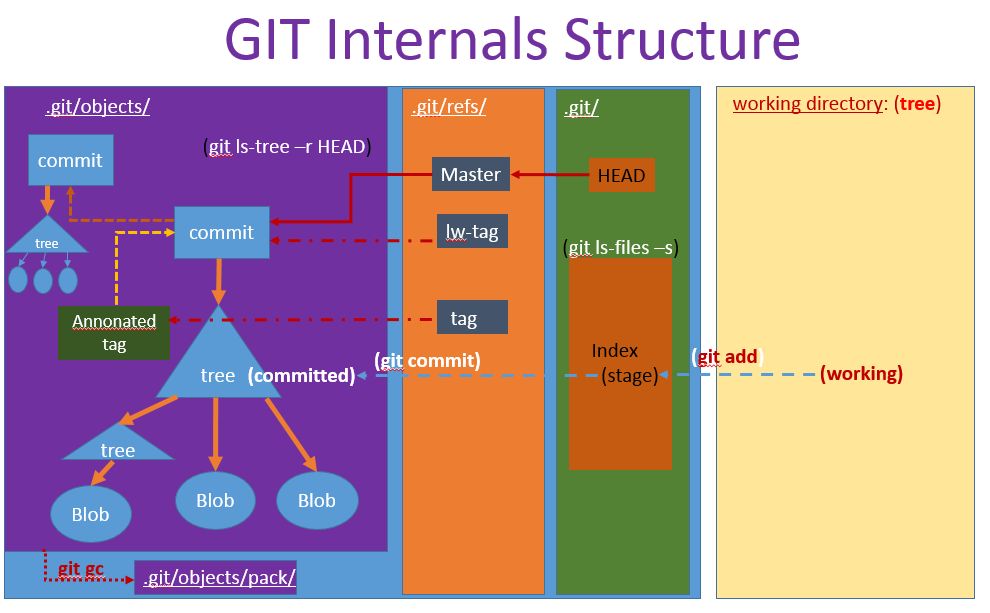
Basics
There are two types GIT repositories: bare and non-bare(working repository). The above showing a working repository, which has a working directory, inside working directory, it contains a hidden directory “.git”, which hold a local copy of git repository. All the magics are inside of “.git” directory.
Let’s take an example by creating an empty repository by “git init”:
weng@weng-u1604:~$ mkdir git-internal-test && cd git-internal-test/
weng@weng-u1604:~/git-internal-test$ git init
Initialized empty Git repository in /home/weng/git-internal-test/.git/
weng@weng-u1604:~/git-internal-test$ find
.
./.git
./.git/HEAD
./.git/config
./.git/hooks
./.git/hooks/pre-rebase.sample
./.git/hooks/applypatch-msg.sample
./.git/hooks/pre-applypatch.sample
./.git/hooks/post-update.sample
./.git/hooks/pre-push.sample
./.git/hooks/prepare-commit-msg.sample
./.git/hooks/commit-msg.sample
./.git/hooks/pre-commit.sample
./.git/hooks/update.sample
./.git/objects
./.git/objects/pack
./.git/objects/info
./.git/refs
./.git/refs/heads
./.git/refs/tags
./.git/info
./.git/info/exclude
./.git/description
./.git/branches
weng@weng-u1604:~/git-internal-test$ As it is shown, “git init” creates a few directories inside “.git” directory to store different type of files such as objects, references, hooks.
Objects
Objects are the key ingridients of GIT repository. “.git/objects” is the directory will hold GIT objects. An object is identified by a 40-character-long string – SHA1 hash of the object’s content. There are four types objects:
There is one important concept in GIT when we are working on files. There are following states of a file:
Let’s create first file, and track how the objects are created, and file status is changed:
weng@weng-u1604:~/git-internal-test$ echo "test file 1" > f1.txt
weng@weng-u1604:~/git-internal-test$ tree
.
└── f1.txt
0 directories, 1 file
weng@weng-u1604:~/git-internal-test$ git status
On branch master
Initial commit
Untracked files:
(use "git add <file>..." to include in what will be committed)
f1.txt
nothing added to commit but untracked files present (use "git add" to track)
weng@weng-u1604:~/git-internal-test$As it is shown f1.txt is created but in untracked state. Now let’s use “git add” to add it into stage area:
weng@weng-u1604:~/git-internal-test$ git add f1.txt
weng@weng-u1604:~/git-internal-test$ find
.
./.git
./.git/HEAD
./.git/config
./.git/hooks
./.git/hooks/pre-rebase.sample
./.git/hooks/applypatch-msg.sample
./.git/hooks/pre-applypatch.sample
./.git/hooks/post-update.sample
./.git/hooks/pre-push.sample
./.git/hooks/prepare-commit-msg.sample
./.git/hooks/commit-msg.sample
./.git/hooks/pre-commit.sample
./.git/hooks/update.sample
./.git/objects
./.git/objects/75
./.git/objects/75/342f57ac22184fe5047ed0b0e82286bc56eea0
./.git/objects/pack
./.git/objects/info
./.git/refs
./.git/refs/heads
./.git/refs/tags
./.git/info
./.git/info/exclude
./.git/description
./.git/index
./.git/branches
./f1.txt
weng@weng-u1604:~/git-internal-test$
weng@weng-u1604:~/git-internal-test$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: f1.txt
weng@weng-u1604:~/git-internal-test$ git cat-file -t 75342
blob
weng@weng-u1604:~/git-internal-test$ git cat-file -p 75342
test file 1
weng@weng-u1604:~/git-internal-test$ Now we see that f1.txt has become a staged/new file. Also we noticed that a new object file “./.git/objects/75/342f57ac22184fe5047ed0b0e82286bc56eea0” is created. This is a blob object file with content of “test file 1”, which is what we put in f1.txt. Now we know/verify how blob object is created.
The f1.txt is only staged,not committed yet. But we can create a tree object for it by using “git write-tree”.
weng@weng-u1604:~/git-internal-test$ git write-tree
741053ae1c317a0205edf9d8a756c486688b7d1a
weng@weng-u1604:~/git-internal-test$ find
.
./.git
./.git/HEAD
./.git/config
./.git/hooks
./.git/hooks/pre-rebase.sample
./.git/hooks/applypatch-msg.sample
./.git/hooks/pre-applypatch.sample
./.git/hooks/post-update.sample
./.git/hooks/pre-push.sample
./.git/hooks/prepare-commit-msg.sample
./.git/hooks/commit-msg.sample
./.git/hooks/pre-commit.sample
./.git/hooks/update.sample
./.git/objects
./.git/objects/75
./.git/objects/75/342f57ac22184fe5047ed0b0e82286bc56eea0
./.git/objects/pack
./.git/objects/info
./.git/objects/74
./.git/objects/74/1053ae1c317a0205edf9d8a756c486688b7d1a
./.git/refs
./.git/refs/heads
./.git/refs/tags
./.git/info
./.git/info/exclude
./.git/description
./.git/index
./.git/branches
./f1.txt
weng@weng-u1604:~/git-internal-test$ git cat-file -t 74105
tree
weng@weng-u1604:~/git-internal-test$ git cat-file -p 74105
100644 blob 75342f57ac22184fe5047ed0b0e82286bc56eea0 f1.txt
weng@weng-u1604:~/git-internal-test$ As it is shown, we created a tree object with SHA1 hash 741053ae1c317a0205edf9d8a756c486688b7d1a, which has the reference to blob object, plus the file name.
Next we verify the commit object:
weng@weng-u1604:~/git-internal-test$ git commit -m "fist commit for f1.txt file"[master (root-commit) c940ba6] fist commit for f1.txt file
1 file changed, 1 insertion(+)
create mode 100644 f1.txt
weng@weng-u1604:~/git-internal-test$ find
.
./.git
./.git/COMMIT_EDITMSG
./.git/HEAD
./.git/logs
./.git/logs/HEAD
./.git/logs/refs
./.git/logs/refs/heads
./.git/logs/refs/heads/master
./.git/config
./.git/hooks
./.git/hooks/pre-rebase.sample
./.git/hooks/applypatch-msg.sample
./.git/hooks/pre-applypatch.sample
./.git/hooks/post-update.sample
./.git/hooks/pre-push.sample
./.git/hooks/prepare-commit-msg.sample
./.git/hooks/commit-msg.sample
./.git/hooks/pre-commit.sample
./.git/hooks/update.sample
./.git/objects
./.git/objects/75
./.git/objects/75/342f57ac22184fe5047ed0b0e82286bc56eea0
./.git/objects/pack
./.git/objects/c9
./.git/objects/c9/40ba63b1bda27738df7b43423fcf1efaf767ce
./.git/objects/info
./.git/objects/74
./.git/objects/74/1053ae1c317a0205edf9d8a756c486688b7d1a
./.git/refs
./.git/refs/heads
./.git/refs/heads/master
./.git/refs/tags
./.git/info
./.git/info/exclude
./.git/description
./.git/index
./.git/branches
./f1.txt
weng@weng-u1604:~/git-internal-test$ git cat-file -t c940ba
commit
weng@weng-u1604:~/git-internal-test$ git cat-file -p c940ba
tree 741053ae1c317a0205edf9d8a756c486688b7d1a
author Wenwei Weng <weweng@gmail.com> 1484639055 -0800
committer Wenwei Weng <weweng@gmail.com> 1484639055 -0800
fist commit for f1.txt file
weng@weng-u1604:~/git-internal-test$
weng@weng-u1604:~/git-internal-test$ cat .git/HEAD
ref: refs/heads/master
weng@weng-u1604:~/git-internal-test$ cat .git/refs/heads/master
c940ba63b1bda27738df7b43423fcf1efaf767ce
weng@weng-u1604:~/git-internal-test$
weng@weng-u1604:~/git-internal-test$ git ls-tree -r HEAD
100644 blob 75342f57ac22184fe5047ed0b0e82286bc56eea0 f1.txt
weng@weng-u1604:~/git-internal-test$ We can see that after commit, “.git/HEAD” is updated to point to “.git/refs/heads/master”, which is pointing to the commit we just made.
Lastly we will verify tag object by using “git tag -a -m”v0.1” V0.1 c940ba”
weng@weng-u1604:~/git-internal-test$ git tag -a -m'version 0.1' V0.1 c940ba
weng@weng-u1604:~/git-internal-test$ find
.
./.git
./.git/COMMIT_EDITMSG
./.git/HEAD
./.git/logs
./.git/logs/HEAD
./.git/logs/refs
./.git/logs/refs/heads
./.git/logs/refs/heads/master
./.git/config
./.git/hooks
./.git/hooks/pre-rebase.sample
./.git/hooks/applypatch-msg.sample
./.git/hooks/pre-applypatch.sample
./.git/hooks/post-update.sample
./.git/hooks/pre-push.sample
./.git/hooks/prepare-commit-msg.sample
./.git/hooks/commit-msg.sample
./.git/hooks/pre-commit.sample
./.git/hooks/update.sample
./.git/objects
./.git/objects/c8
./.git/objects/c8/62407c91ee28f496970ce0585b216681f19c1e
./.git/objects/75
./.git/objects/75/342f57ac22184fe5047ed0b0e82286bc56eea0
./.git/objects/pack
./.git/objects/c9
./.git/objects/c9/40ba63b1bda27738df7b43423fcf1efaf767ce
./.git/objects/info
./.git/objects/74
./.git/objects/74/1053ae1c317a0205edf9d8a756c486688b7d1a
./.git/refs
./.git/refs/heads
./.git/refs/heads/master
./.git/refs/tags
./.git/refs/tags/V0.1
./.git/info
./.git/info/exclude
./.git/description
./.git/index
./.git/branches
./f1.txt
weng@weng-u1604:~/git-internal-test$ git cat-file -t c8624
tag
weng@weng-u1604:~/git-internal-test$ git cat-file -p c8624
object c940ba63b1bda27738df7b43423fcf1efaf767ce
type commit
tag V0.1
tagger Wenwei Weng <weweng@gmail.com> 1484639367 -0800
version 0.1
weng@weng-u1604:~/git-internal-test$ git show-ref --tags
c862407c91ee28f496970ce0585b216681f19c1e refs/tags/V0.1
weng@weng-u1604:~/git-internal-test$ cat .git/refs/tags/V0.1
c862407c91ee28f496970ce0585b216681f19c1e
weng@weng-u1604:~/git-internal-test$ When the repository grows, to save disk space, we can use “git gc” to pack the objects:
weng@weng-u1604:~/git-internal-test$ git gc
Counting objects: 4, done.
Delta compression using up to 2 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (4/4), done.
Total 4 (delta 0), reused 0 (delta 0)
weng@weng-u1604:~/git-internal-test$ find
.
./.git
./.git/COMMIT_EDITMSG
./.git/HEAD
./.git/logs
./.git/logs/HEAD
./.git/logs/refs
./.git/logs/refs/heads
./.git/logs/refs/heads/master
./.git/config
./.git/hooks
./.git/hooks/pre-rebase.sample
./.git/hooks/applypatch-msg.sample
./.git/hooks/pre-applypatch.sample
./.git/hooks/post-update.sample
./.git/hooks/pre-push.sample
./.git/hooks/prepare-commit-msg.sample
./.git/hooks/commit-msg.sample
./.git/hooks/pre-commit.sample
./.git/hooks/update.sample
./.git/packed-refs
./.git/objects
./.git/objects/pack
./.git/objects/pack/pack-19eeb5192ba7924b412bce57e60843e28a4eea51.pack
./.git/objects/pack/pack-19eeb5192ba7924b412bce57e60843e28a4eea51.idx
./.git/objects/info
./.git/objects/info/packs
./.git/refs
./.git/refs/heads
./.git/refs/tags
./.git/info
./.git/info/exclude
./.git/info/refs
./.git/description
./.git/index
./.git/branches
./f1.txt
weng@weng-u1604:~/git-internal-test$As it is show all the object files are packed into two files: *.pack and *.idx. Even though all object files are packed, GIT still works normally.
References
Reference files are created to manage/refer to objects inside repository. Each branch has a head reference which is stored under “.git/refs/heads/branch-name”. The file “.git/HEAD” contains the “path + filename” which is the current active branch. The following example shows that HEAD is current active branch “master”, and its last commit is object with hash c940ba63b1bda27738df7b43423fcf1efaf767ce.
weng@weng-u1604:~/git-internal-test$ cat .git/HEAD
ref: refs/heads/master
weng@weng-u1604:~/git-internal-test$ cat .git/refs/heads/master
c940ba63b1bda27738df7b43423fcf1efaf767ce
weng@weng-u1604:~/git-internal-test$When “git checkout
Reset and checkout
An easier way to think about reset and checkout is through the mental frame of Git being a content manager of three different trees. By “tree” here we really mean “collection of files”, not specifically the data structure.
Reset
reset moves the current active branch that HEAD is pointing to. Then depending on the option (–soft, –mixed, –hard) given perform different actions.
Assume intially we have following:
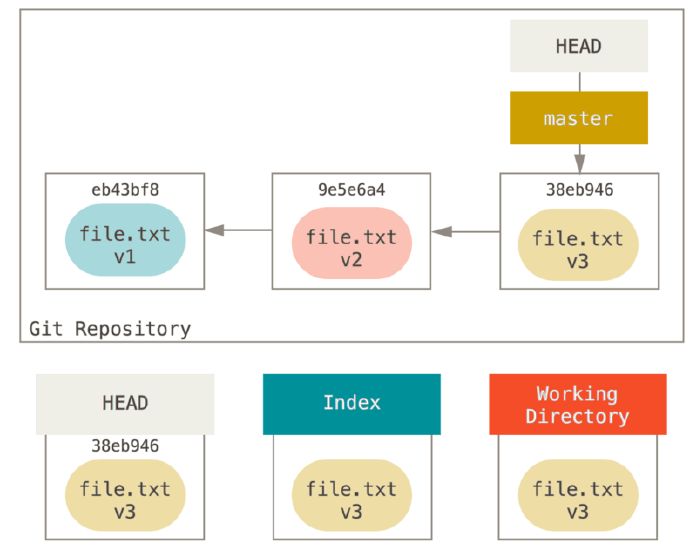
(note: HEAD~ means back to previous first commit, HEAD~2 means back to previous 2nd commit so on…)
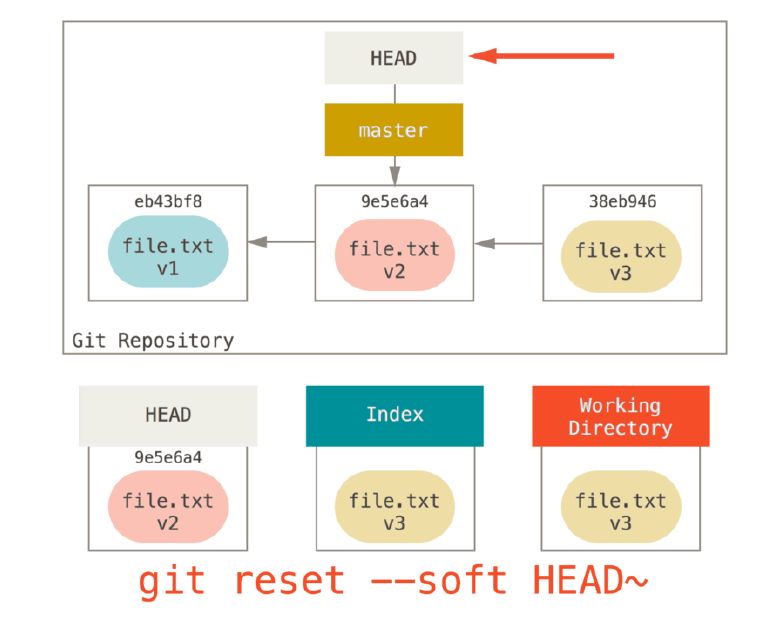
git reset –soft HEAD~
This will only move HEAD point to previous commit, without updating index and working directory.
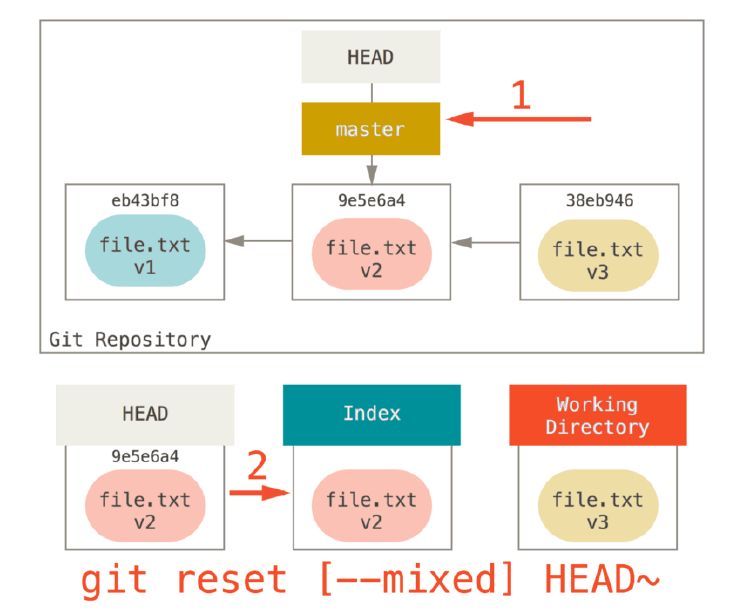
git reset –mixed HEAD~
This will only move HEAD point to previous commit, and copy files to index/staging area, without updating working directory.
git reset –hard HEAD~
This will move HEAD point to previous commit, and copy files to index/staging area and working directory to make them all consistent.
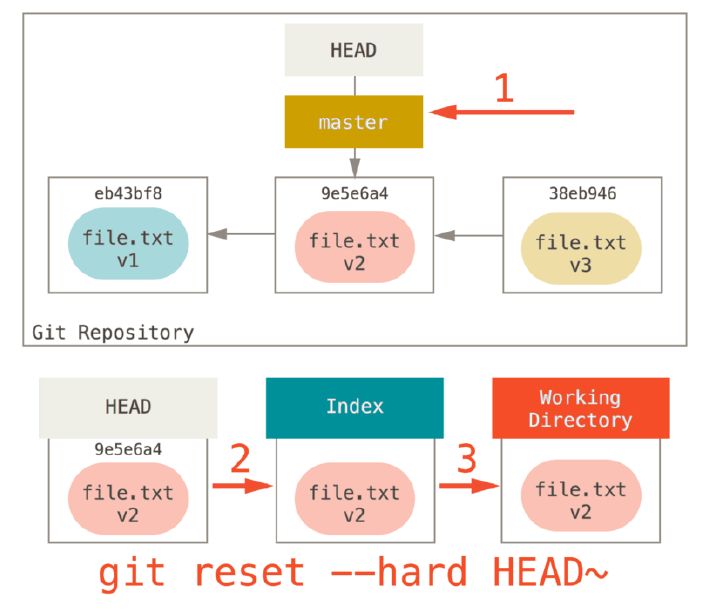
git reset filenmae
This will cause git copy the file version from HEAD is pointing to Index/staging area, which is bascially unstage the file, which is the opposite of “git add”.
git reset [commit-HASH] filename
This will cause git copy the file from given commit is pointing to Index/staging area. Here is really show GIT as content tracking system instead of version tracking system. To do the same in clearcase, you would specify the file version number, here in GIT, there is no version number, all information is tracked though SHA1 hash, so you have to specify commit SHA1 hash to copy the old version file out. In fact, you can use commit SHA1 hash, find associated tree object, then file the filename SHA1 hash from tree object, and then use “git cat-file -p file-SH1-HASH” to print out the file content!
Checkout
It is very close to git reset –hard, two options: with and without path
git checkout branch-name
First, unlike reset –hard, checkout is working-directory safe; it will check to make sure it’s not blowing away files that have changes to them. Actually, it’s a bit smarter than that – it tries to do a trivial merge in the Working Directory, so all of the files you haven’t changed in will be updated. reset –hard, on the other hand, will simply replace everything across the board without checking. The second important difference is how it updates HEAD. Where reset will move the branch that HEAD points to, checkout will move HEAD itself to point to another branch.
git checkout branch-name file-name
The other way to run checkout is with a file path, which, like reset, does not move HEAD. It is just like git reset [branch] file in that it updates the index with that file at that commit, but it also overwrites the file in the working directory. It would be exactly like git reset –hard [branch] file (if reset would let you run that) – it’s not working-directory safe, and it does not move HEAD. Also, like git reset and git add, checkout will accept a –patch option to allow you to selectively revert file contents on a hunk-by-hunk basis.
Subscribe via RSS